训练模式通过训练软件识别特定字符来提高具有装饰性或特殊字体(例如数学符号)的文档的OCR识别质量。在训练模式下,会创建一个用户模式,可以在对整个文本执行OCR时应用该模式。默认情况下,“训练阅读”选项是禁用的,如果需要,需要启用。
创建和训练用户模式
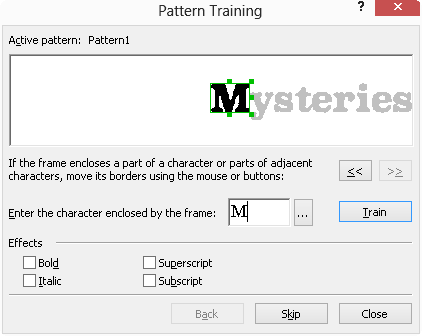
注意:不建议在其他情况下使用训练模式,因为与花费在训练上的精力和时间相比,识别质量的增益是最小的。
另请注意:您只能训练ABBYY FineReader阅读识别语言的字母表中包含的字符。
ABBYY是一个很好的工具,但有时它会出错。区域可能被错误地分析和/或完全遗漏。当这种情况发生时,您可以重新指定不正确和缺失的区域。您可以使用界面中的区域编辑工具:
创建一个新区域
的工具中单击一个工具图像编辑框左侧的窗口:
 此符号将绘制一个识别区域
此符号将绘制一个识别区域
![]() 此符号将绘制一个文本区域
此符号将绘制一个文本区域
 此符号将绘制一个图片区域
此符号将绘制一个图片区域
 此符号将绘制一个具有背景照片和文本覆盖的区域
此符号将绘制一个具有背景照片和文本覆盖的区域
 此符号将绘制一个表区域
此符号将绘制一个表区域
在指定要创建的区域类型后,按住鼠标左键并拖动光标选择相应的区域。
完成后,您需要通过单击编辑窗口顶部的“阅读页面”按钮,或右键单击并从出现的菜单中选择“阅读”来重新阅读页面。别忘了存钱!
编辑图像是创建高质量最终文档不可或缺的一步。ABBYY允许在处理文档时进行一些简单的编辑。


